Who Watches the Watchers?
A presentation at DevFestMN Focus: ML + AI 2019 in in Minneapolis, MN, USA by Jason St-Cyr

Who Watches the Watchers? #ethics in a #machinelearning world
Hello everybody, it’s so great to be here today and hear all these great sessions. My name is Jason, and over the next 40 minutes or so I’m going to talk about something near and dear to my heart: Ethics in Software Engineering. But more specifically about ethics and bias in the machine learning systems we’re dealing with today
#ethics in the news...
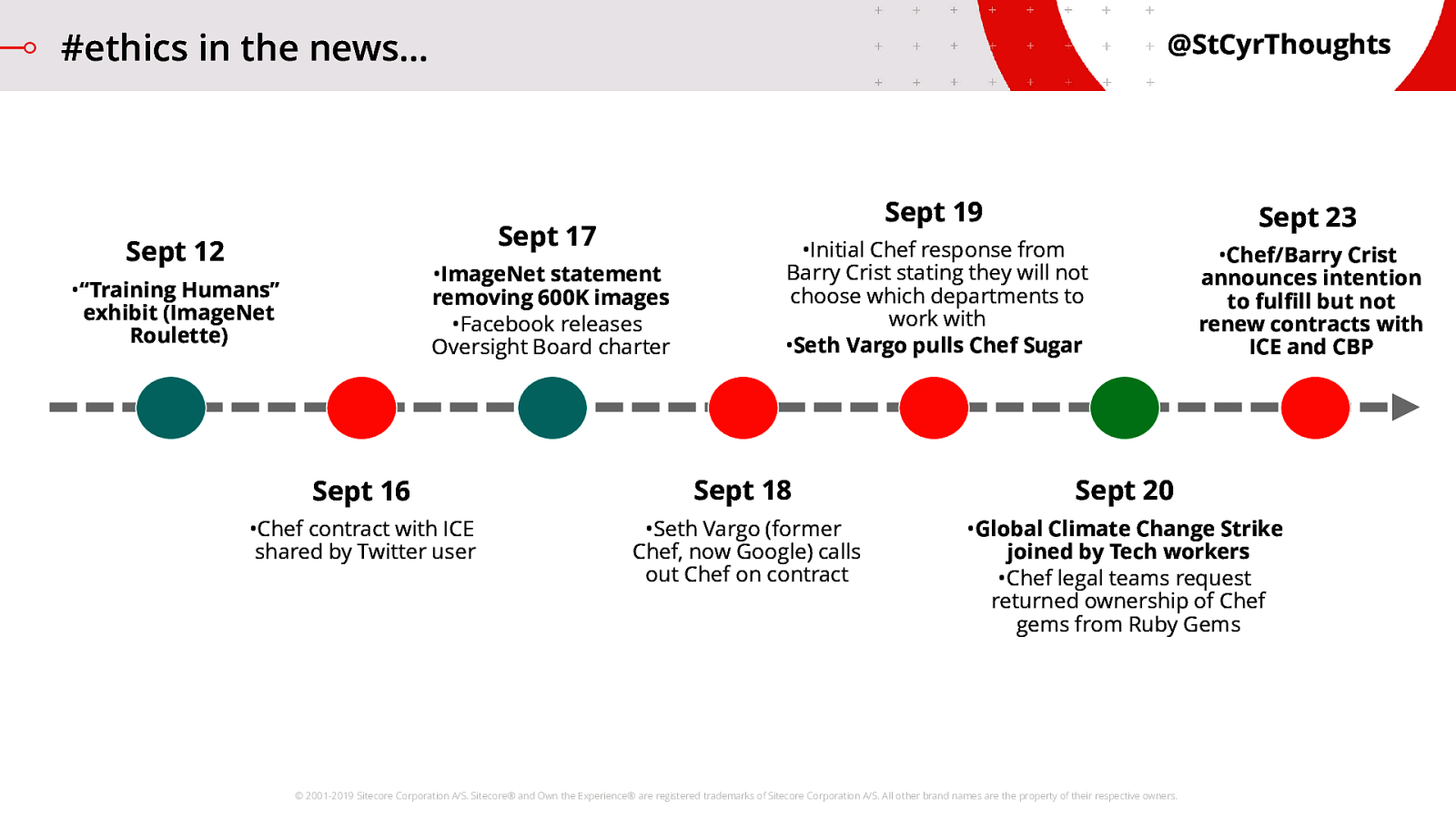
The news is filled with stories about deep fakes, facial recognition systems, and all kinds of cool things being used for potentially bad purposes, and we need to talk about how we work in this world to stay on the right side of history. Here’s a sample of the news from the last few weeks:
- The whole ImageNet Roulette thing from Kate Crawford and Trevor Paglen highlighted the potential downsides of ML running on bad data, and then once the news started breaking on this and the story caught fire ImageNet made sure to get out in front of it.
- We’ve got tech workers banding together to join a climate change walkout.
- …and the entire Chef thing has been so bizarre. I don’t think we’ve seen the end of that story yet, but the move from outrage to action to reaction was swift and impactful. However you stand on these particular topics, there is no denying that we all are involved in this discussion today. This is just a small sample from a small period of time.
One day, one of us is going to need to be a Seth Vargo, or a Kate Crawford, or a Barry Crist. Some of these issues are ones of Ethical technology, and some are about Responsible technology.
TIMELINE REFERENCES:
- September 12: Training Humans exhibit (ImageNet Roulette) opens (by Kate Crawford, Trevor Paglen
- September 16: Chef contract with ICE shared by Twitter user: https://twitter.com/shanley/status/1173692656192385024
- September 17: ImageNet statement committing to removing/sanitizing 600K images in Person category
- September 17: Facebook releases the charter for its Oversight Board: https://newsroom.fb.com/news/2019/09/oversight-board-structure/
- September 18: Seth Vargo (former Chef engineer, now Google) calls out Chef on ICE contract: https://twitter.com/sethvargo/status/1174451060263530502
- September 19: Initial response from Chef stating they should not choose which government agencies they should work with: https://blog.chef.io/2019/09/19/chefs-position-on-customer-engagement-in-thepublic-and-private-sectors/
- September 19: Many comment on the issue, including Jez Humble (DevRel Google Cloud) discusses turning down contracts: https://twitter.com/jezhumble/status/1174872923603030016
- September 19: Seth Vargo pulls Chef Sugar: https://github.com/sethvargo/chefsugar
- September 20: Global Climate Change Strike joined by Tech Workers: https://www.cnbc.com/2019/09/20/global-climate-strike-facebook-amazon-andtwitter-workers-walk-out.html
- September 20: Chef legal teams request returning ownership of Chef gems: https://blog.rubygems.org/2019/09/20/chef-ownership.html
- September 23: Chef announces intention to fulfill but not renew contracts with ICE and CBP: https://blog.chef.io/2019/09/23/an-important-update-from-chef/

Responsible AI vs Ethical AI
What’s the difference? During a discussion I had on this Responsible AI vs Ethical AI earlier in the year, I think Virginia Dignum captured it best. Sometimes, we are building something or acting in a way that is doing the ‘right’ thing. But sometimes, it’s about HOW we are building or acting, being responsible. That’s what I’d like to focus on today, to keep us contained. How do we do the thing right?

All my instincts they return...
Now I’m not a data scientist. I’m not some uber-math guy. I’m definitely not playing with TensorFlow and Jupyter on the weekends. That’s just not who I am. I built my software engineering career around providing solutions to problems, primarily with web-based applications. Eventually, I was running teams to solve bigger problems and looking at things more holistically. What I’m seeing right now with machine learning activities is very similar to what has been happening with other new technologies when they first start gaining mainstream popularity. So I’m just a boy, standing in front of an industry, asking it to please take the time to pause and think about the impact of what you are doing. Img: Alex Eylar (https://www.flickr.com/photos/hoyvinmayvin/)

Not being an alarmist...
But let’s get something out of the way. This talk is not meant to bepare for Ragnarok. This is not that type of session. What we’re here to talk about today is a situation happening right now which is opening up new ethical scenarios that we need to be prepared to address.

A scenario for failure
I’m working in the digital marketing space, so the scenario we’re seeing ourselves in has some specific factors. We have massive customer data stores now, and a market that is obsessed with beating the competition by going faster and faster and faster. Artificial Intelligence, Deep Learning, Machine Learning… all the hype you hear around this technology is adding fuel to that race. We have too much data, so we need new innovations to act on that data. We combine that driving force, with new innovations, and a whole lot of new processes and we are put in a precarious situation. Right now we’re moving so fast that we are asking if we CAN do something, not if we SHOULD. And that’s a problem. As an example of one of those innovations, let’s have a listen to an AI personal assistant on a phone call.

Checking restaurant hours
[AUDIO FILE PLAYS] In this example, the caller was the AI. But honestly, it could easily have been the restaurant answering with an AI. There is another example of Google Duplex where the assistant books a hairdresser appointment, and others where it can handle interruptions and resume the conversation. This, and other examples, were demo’d by Google as part of some of the technology innovations they are working on. The reaction was… 7
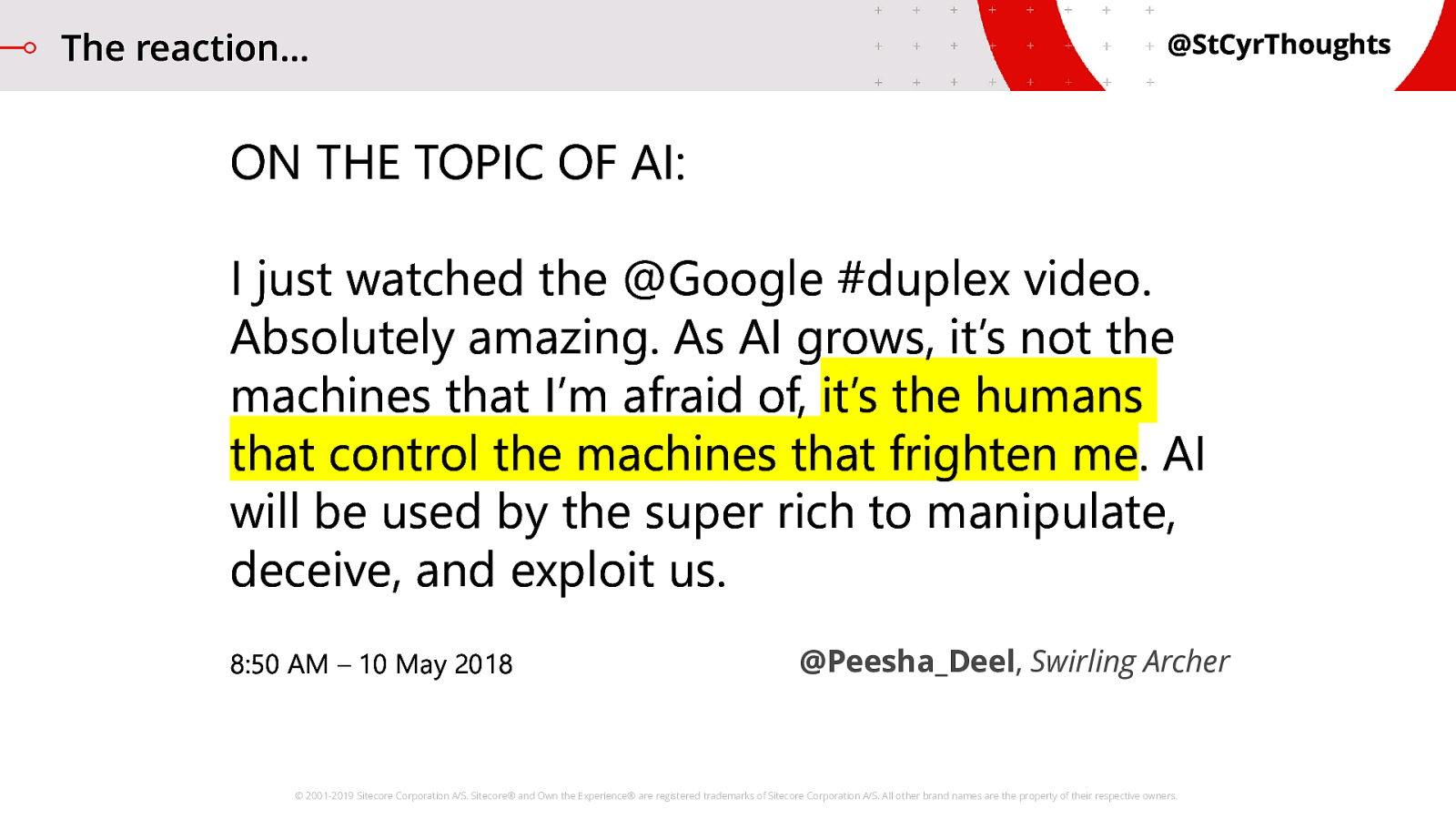
The reaction...
… not entirely positive.

The reaction…
The tech behind this is amazing, the advancements made here are truly impressive.

The reaction…
and “horrifying”.

The reaction…
The general feeling was that people wanted to know they were talking to a person, or a machine. They did not want to be fooled.
Since this demo was released, Google has responded to the feedback and clarified that they plan on having the assistant self-identify, but the fact of the matter is the technology does not HAVE to self-identify. It could just keep fooling people.
This identification decision is not based on CAN. It’s based on SHOULD.
In science, we often have researchers focusing deeply on solving a problem and trying to find the way that they CAN do something. At some point in the process, though, somebody needs to be asking the question:

Jeff Goldblum had it right!
“Umm… should we be doing this?”

Who asks the question?
So who is asking that question? Who is supposed to be watching over these advancements? Who is making sure AI and ML are being done ethically? Who will guard us against bias in the system? Even unconscious bias?
During my own research, I came across an article that mentioned a paper on neural networks for gang crime classification. It was presented at a conference, and some of the audience asked questions about the ethics of classifying somebody as a gang member. The Computer Scientist, a Ph.D, working at Harvard, said “I’m just an engineer”. That just doesn’t cut it. There is no cop out. There is no “I’m just a [WhateverYourJobIs]”. We’re all in this. There is no tolerance from society for us to abdicate responsibility to somebody else’s shoulders.
From: https://www.infoq.com/presentations/unconscious-bias-machine-learning
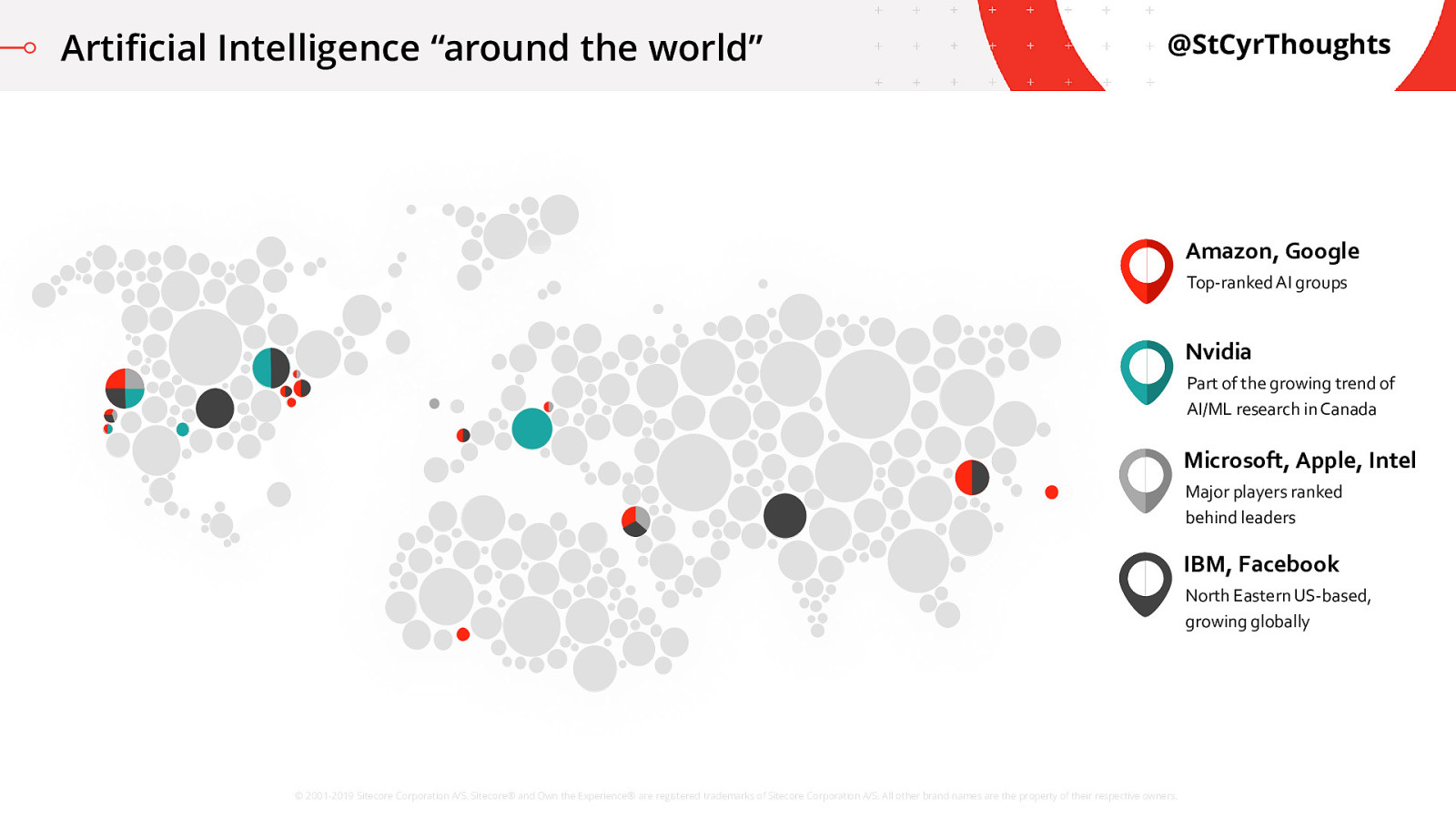
Artificial Intelligence “around the world”
Okay, so it’s fine to say we all have a responsibility, but not all of us are leading the charge of artificial intelligence research in the world. If you look at the top companies that are investing in major research “around the world” into artificial intelligence and machine learning, they all have an unfortunate diversity problem. Primarily they are based out of North America, specifically the west coast, these groups can be doing their best but the lack of diversity in their teams leads to unconscious bias. These groups have been growing outwards in recent years, as you can see in this map, to try to add more diversity and more reach into other cultures. They have recognized that they do not have a global view of the problem, and it is impacting their ability to deliver solid solutions. However, the growth in diversity is limited and slow. And you’ll notice a lot of GREY up there on the screen. Not to mention an entire half of the world not even showing up. We are a long way off from a balanced workforce in artificial intelligence research. And this means we are a long way off from removing unconscious bias.

Digital Marketing and Bias
I don’t want to be reductionist on the concept of ethics here, but there’s a reason I’m focusing in a little bit on bias. I work in a digital marketing industry that is intent on maximizing the capability to impact as many people as possible, automating ANYTHING and EVERYTHING they can. That can lead to some… undesirable situations. I’m sure many of you have had the pleasure of being addressed with the “Dear [First Name]” email.
Impact of bias: Exclusion
So how does unconscious bias introduce an issue in an ML-based digital marketing scenario? Let me tell you a quick story of a biased algorithm leading to exclusion of a certain group. A long time ago, in a magical kingdom of digital marketing,
Impact of bias: Exclusion
Some visitors, when they visited the website
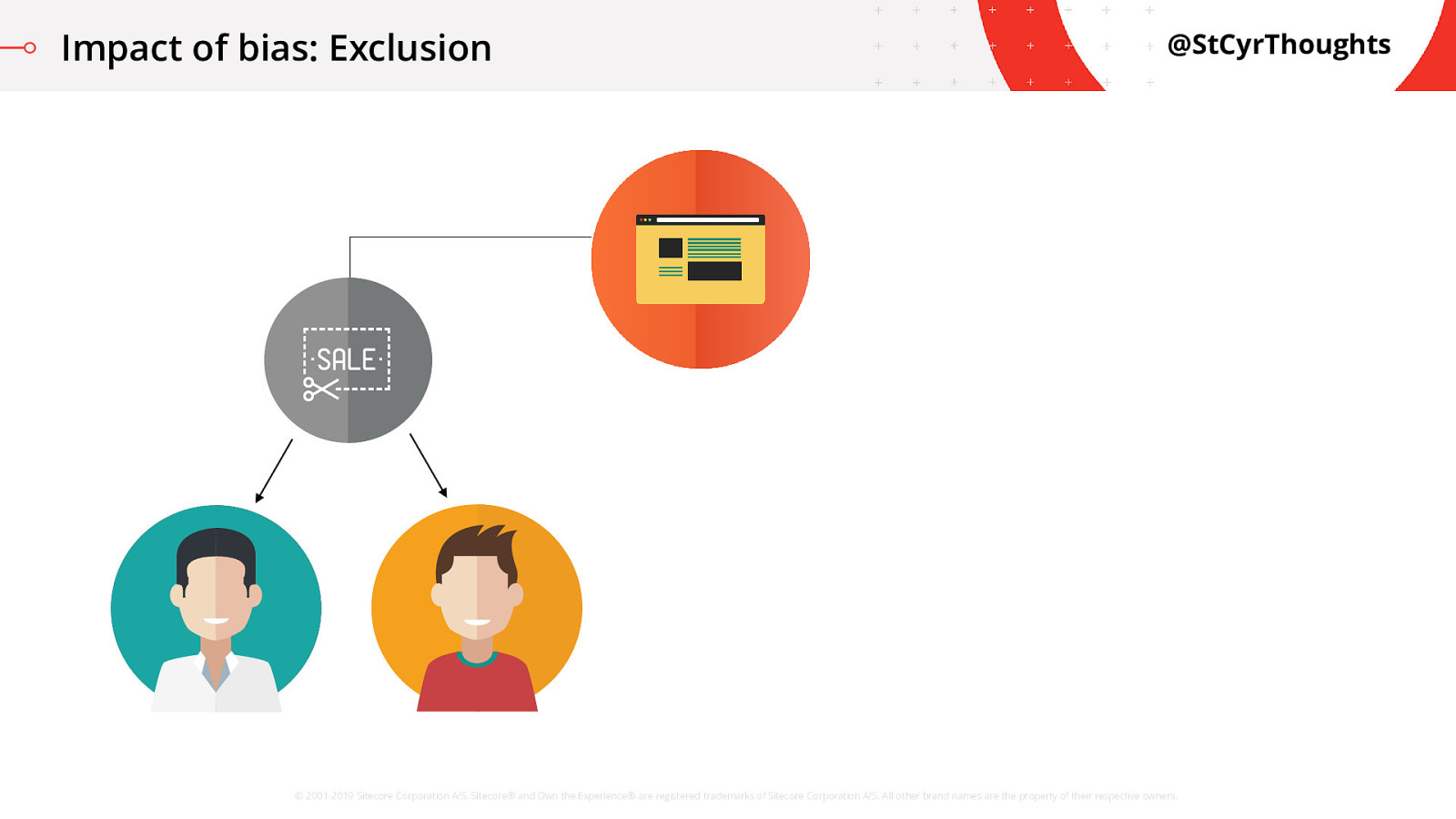
Impact of bias: Exclusion
were offered a big discount on their next purchase.
Impact of bias: Exclusion
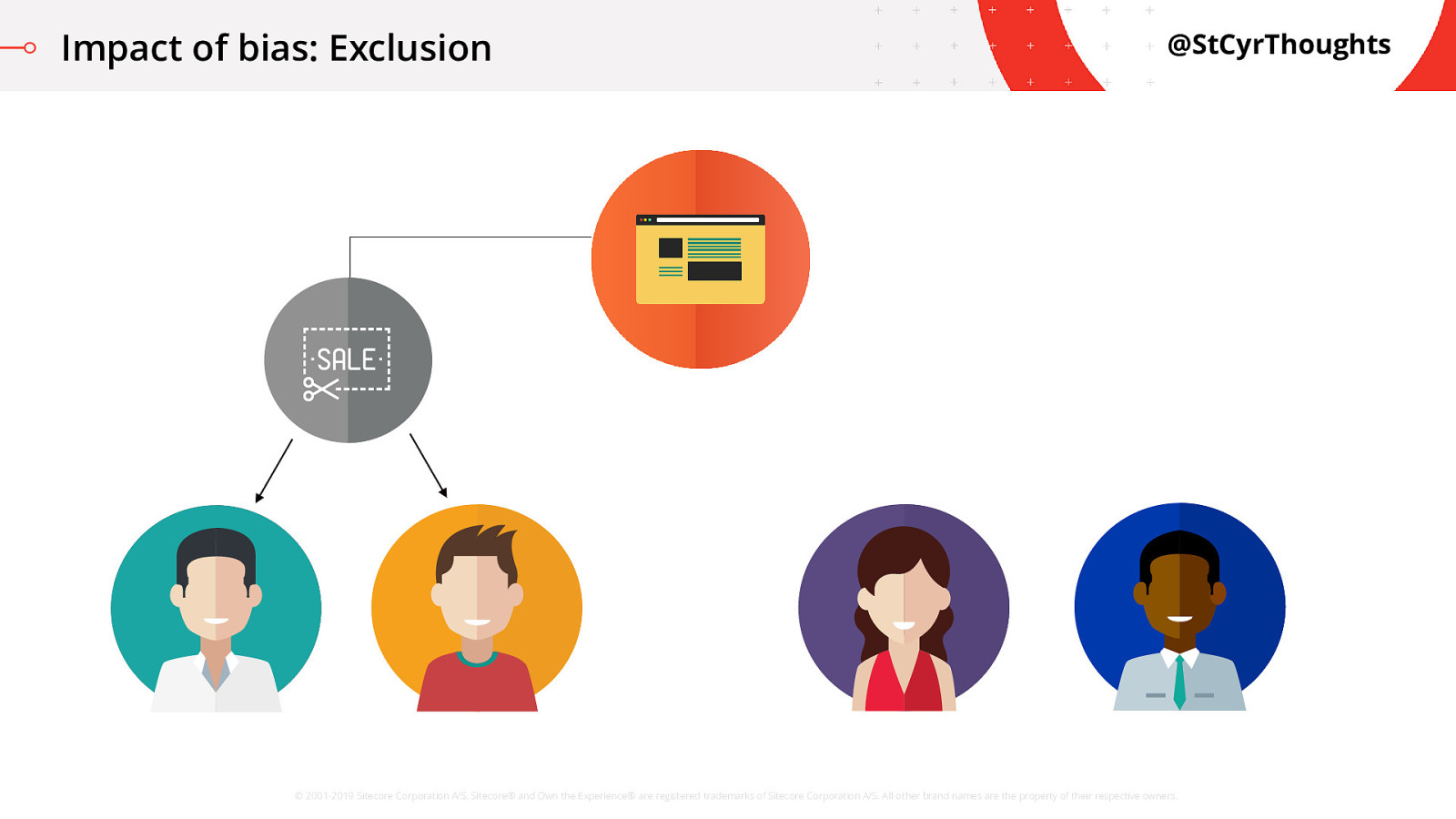
Other visitors were never receiving that discount
Impact of bias: Exclusion
and were only directed to add items to their cart for purchase.
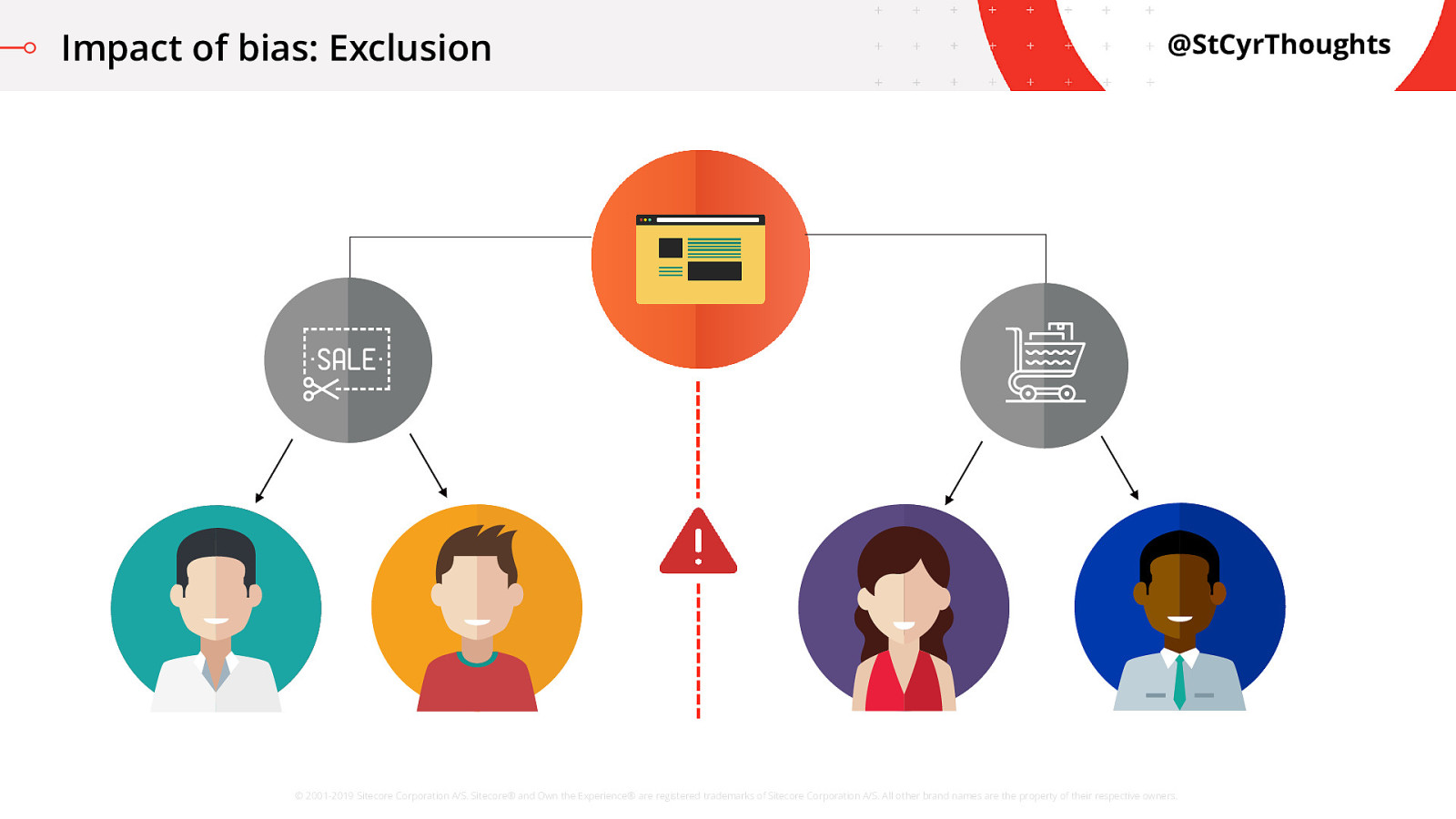
Impact of bias: Exclusion
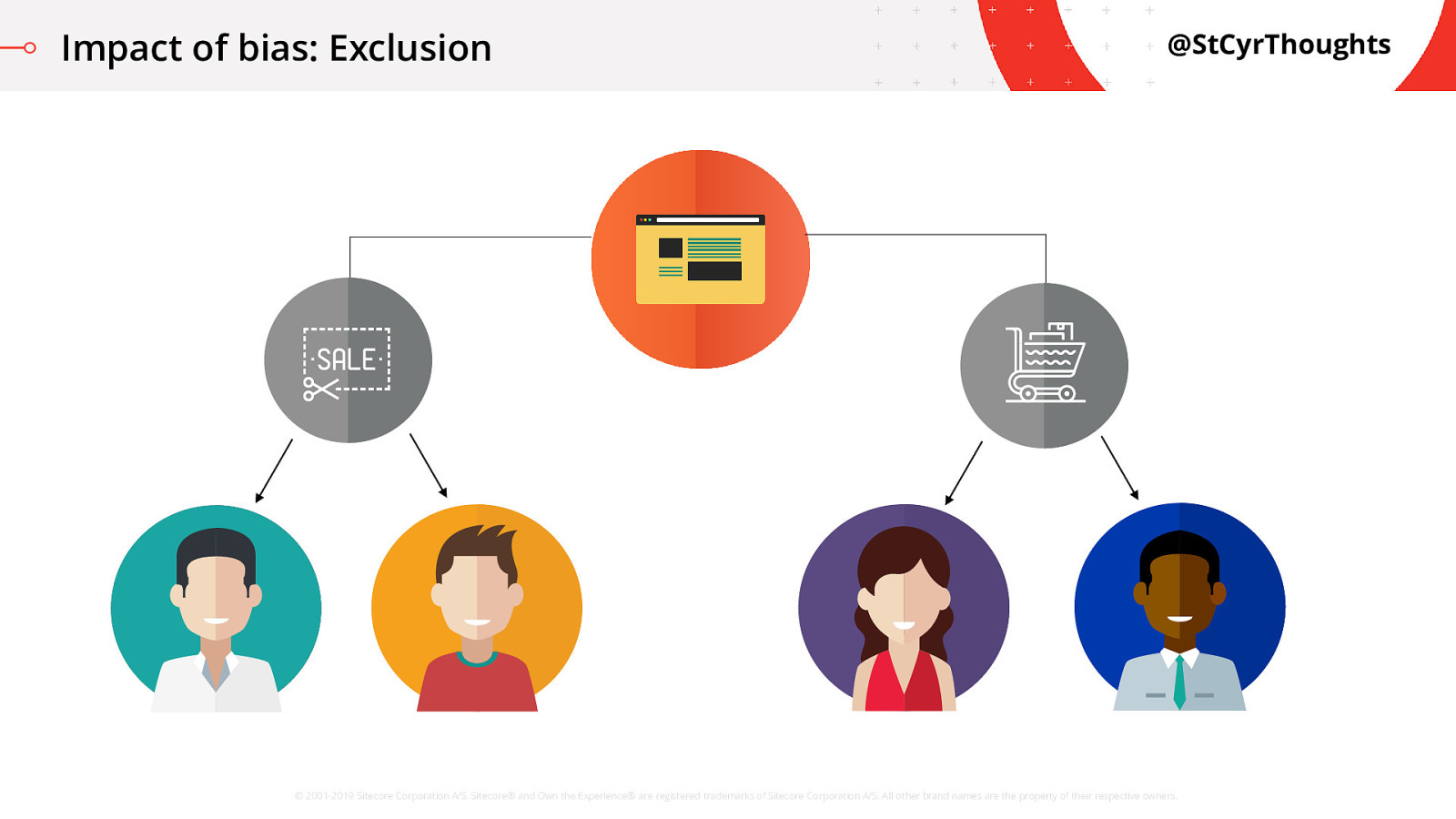
The algorithm had predicted, based on historical customer data, that white males have a higher chance of conversion on high end items when provided a promo, so the algorithm was only scoring those individuals with the right score to get a discount.
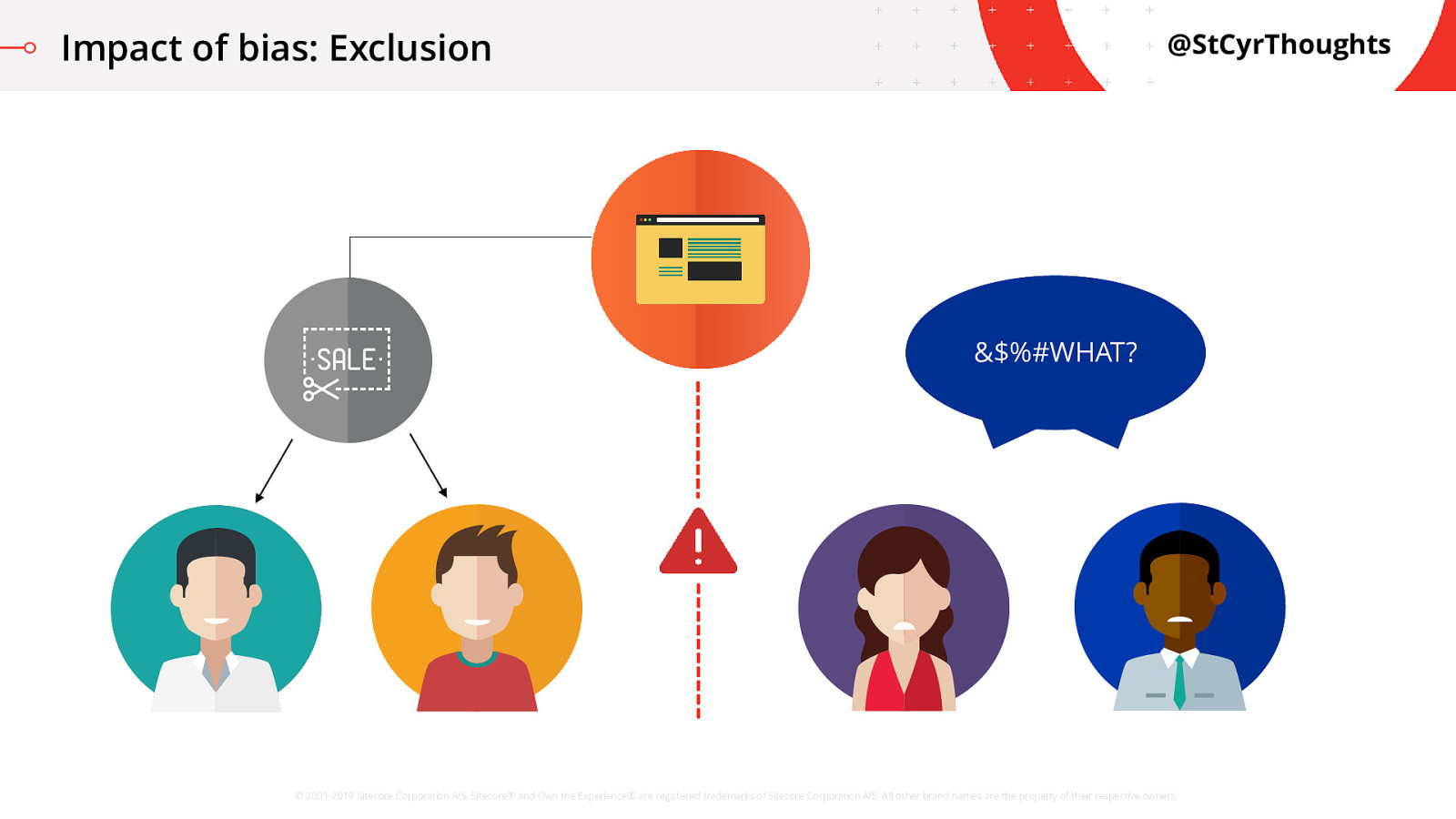
Impact of bias: Exclusion
Word travelled far and wide in the kingdom via social media about the situation and suddenly there was a public relations nightmare! How did this happen?
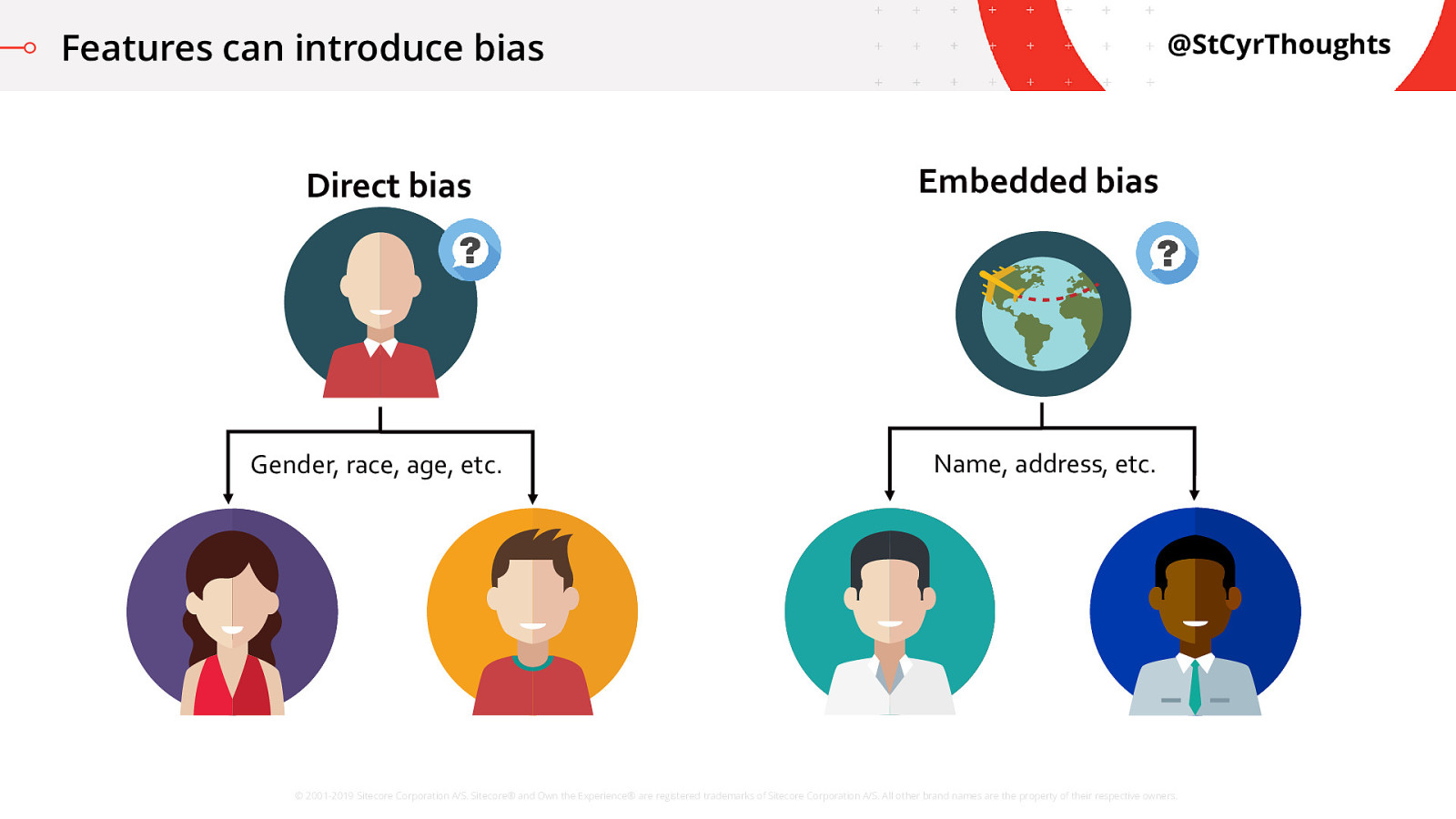
Features can introduce bias
If the Algorithm is just mathematically looking at the data we have, how can it be unfair? Isn’t it just representing the real data we have?
The fact is that the features we use when building our models impact the decisions. We might be directly influencing bias in the system with something obvious like a gender, or age, or race feature.
However, simply ignoring those features, also known as “blindness”, doesn’t always work. Some of our attributes are also embedded in other variables like our social networks, our education level, where we live, even our names.
In our story, the algorithm was learning based on projection data using Gender and Address features which calculated higher scores for men who lived in traditionally white neighbourhoods. It was scoring individuals based on demographic data, not on how the users behaved. This type of segmentation can create unfair advantages.

COMPELLING TALE, CHAP!
You’re probably saying to yourself “That’s a cool story, bro, interesting problem you have there. But I don’t do digital marketing at my job”.
As you’ve seen from the other presentations today… machine learning and artificial intelligence is being put into pretty much every digital aspect of our lives. So what are we going to do about it? It’s great to highlight a problem, but we need solutions too. I want to talk through a few areas where we can all help and really make an impact on making things better.
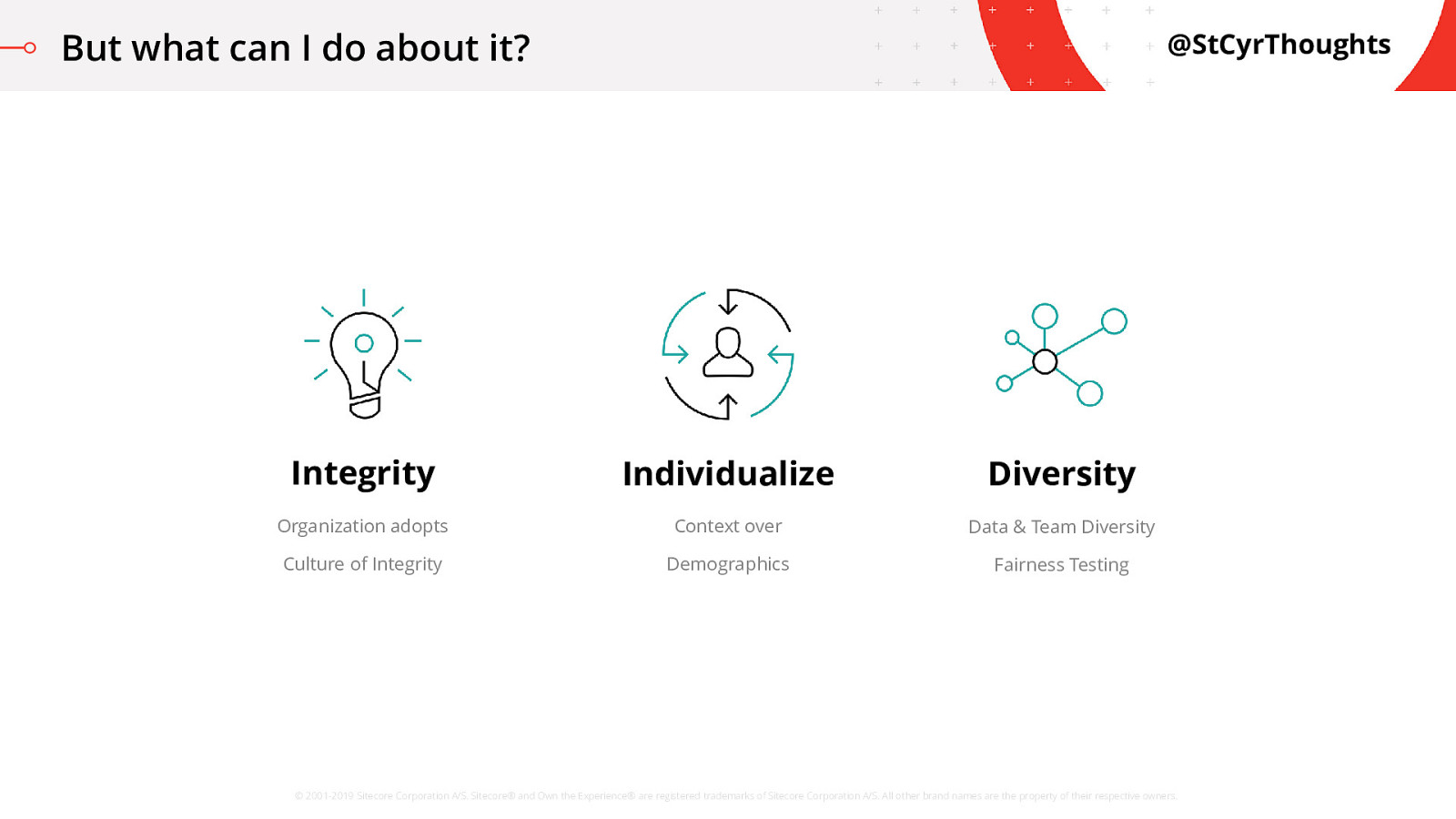
But what can I do about it?
One area is integrity, which is a nice professional way of saying “hey, let’s not be jerks about this” Another is making sure we value behavior of the individual over segmentation. Individualization is the new personalization hype! Finally, we’ll talk about diversifying both the data, and our teams that work on data, and some cool math we can do here for testing fairness.

Integrity

Integrity is hard
So what is a Culture of Integrity? It sounds like a bunch of fluffy words you would hear from an organizational process improvement consultant. You are probably right, but that doesn’t mean it isn’t a huge value to an organization!
At the core of anything we do there needs to be a belief that we are doing the “right thing”. We need to know our colleagues are doing the “right thing”. We need to know that management and executives are doing the “right thing”.
I’m “air-quoting” here because one of the most critical problems is : What is the right thing to do in a world of grey-area scenarios?
Start Learning If you are wanting to be more deliberate about ethics in your organization, the first thing you need to start doing is research. A lot of it. This is not a new field and a lot of organizations have gone through this cultural transformation. You can learn a LOT from the successes and failures of others.
It takes a village Adoption across the organization is a huge challenge. This is not unique to ethics and integrity. I have seen the same with adopting agile delivery frameworks, DevOps cultures, and Continuous Improvement practices. If we look at DevOps culture as an example, there is an inherent belief behind DevOps that we are all working together, as a single team, with a shared responsibility. This spans from idea, to launch, and continuing through the entire life-cycle of software. DevOps is a cultural shift that needs to happen throughout an organization to make DevOps succeed. The same is true for handling ethics in machine learning. Everybody needs to be involved to build a deliberate and shared culture that supports thinking about problems and solutions and whether something SHOULD be done.

Organizations mimic behavior of their leaders!
Integrity starts from the top We look to our leaders to see how we should act. If management is cutting corners, following unethical practices, overworking… employees will be tempted to emulate those practices seeing as they are being rewarded.
Similarly, if leadership is seen to be deliberate, transparent, and is encouraging ethical and unbiased decision-making and behaviour, employees will understand that those behaviours are valued by the organisation and follow suit.

Has to be OKAY to say things are NOT OKAY
Build a support system We need to build strategies of how everybody in the organization can weigh the outcomes in different scenarios by building ethical considerations into everyday decision-making. There have to be individuals championing integrity within the organization, and voicing support for colleagues doing the right thing. There have to be examples and training provided for employees so that everybody can learn to see a scenario through a different lens and say “Oh, yeah, I never thought about it that way.”
Organizations should be looking at their Codes of Conduct to ensure that they contain not just regulations, but also reflect the values of the organization. We do not need a billion rules and punishments and a team of Ethics Police to monitor behaviour!
It has to be OK to say things are NOT OK For this to work, everyone needs to feel comfortable raising an ethical concern, even about something they did themselves. The working environment needs to be a safe space where concerns can be brought forward without fear of reprisal, loss of status, or impact to one’s career. Individuals need to be able to stand up, own a mistake, and not feel like they need to shift the fault away from themselves. We need to move away from the blame-game!
And… people need to feel comfortable to ask if we SHOULD be doing something.

Ultimately YOU are responsible. But not everyone may agree.
This sounds like somebody else’s problem Another big challenge for adoption is that almost universally, people believe two things to be true: They are excellent drivers, and; They are ethical employees It is one of the most difficult things for somebody to be able to recognize their own bias. This is what is known as unconscious bias. Every person in the organization may influence how a particular algorithm, model, or process is defined and built. If we want to do that ethically, we need to ensure that all individuals involved in the process have the support to be able to consider the ethical implications of their decisions.

Individualize - Context over Demographics
So while you are on your massive quest to bring about a culture of integrity to the entire organization, there is some tactical stuff you can do too.
Think about your user as an individual, not a segment.

Behavior wins.
I did a webinar recently on taking personalization to the next step of individualization, and I discussed a little on why segmentation is just not cutting it anymore. The essential concept was that if we place more value on the behavior of a user and their current context over things like demographic data, we can cater to each customer for who they are, rather than trying to make assumptions.
The other issue with demographic data is that it reinforces existing biases within our cultures. There is a case where, due to the existing distribution of men in high-paying executive jobs, they were the only ones seeing job ads for executive positions. This means we start doubling-down on our existing issues by using these unfair assumptions in our models.

Track it. Safely.
Now one of the very difficult things about targeting individuals is that if you want to leverage an individual’s behavior, that you means you have to track and store that individual’s behavior.
That’s a lot of data. Potentially a lot of SENSITIVE data.
You need to find a way to track it securely. To store it securely. To manage it with the individual’s privacy in mind. So we’re bringing a whole new layer of ethics into the situation, plus the challenge of building trust with the individual to give us this data and trust us to manage it fairly.
Once we have the data, we can deliver better experiences, but it is so very important to do so with a mind on privacy. We should already be doing this with the demographic data we are collecting, but often times folks aren’t used to how to do this with behavioral data as well.

Blindness is not a cure.
Now, as I said before, being blind to the demographic features is not a silver bullet. There may be elements in a user’s context or behavior that may lead to unfair assumptions. But we are talking here about what we can do to be better!

Context takes time
One thing I should mention is that demographic data is easy. We can ask for it, get it, then immediately use it.
Learning about a user based on how they actually behave over time and at a given moment takes a lot of data. And a lot of time. Machine Learning can process that data, but it needs that data set to work with first.
Some fun with demographics!
Okay, let’s have some fun with this individualization bit with something I love: music. I always love messing with the recommendation algorithms based on my music catalog, I’m sure you do too! So let’s do a little group test to reinforce why demographics are terrible…
We’re going to look at some songs, and then choose one…
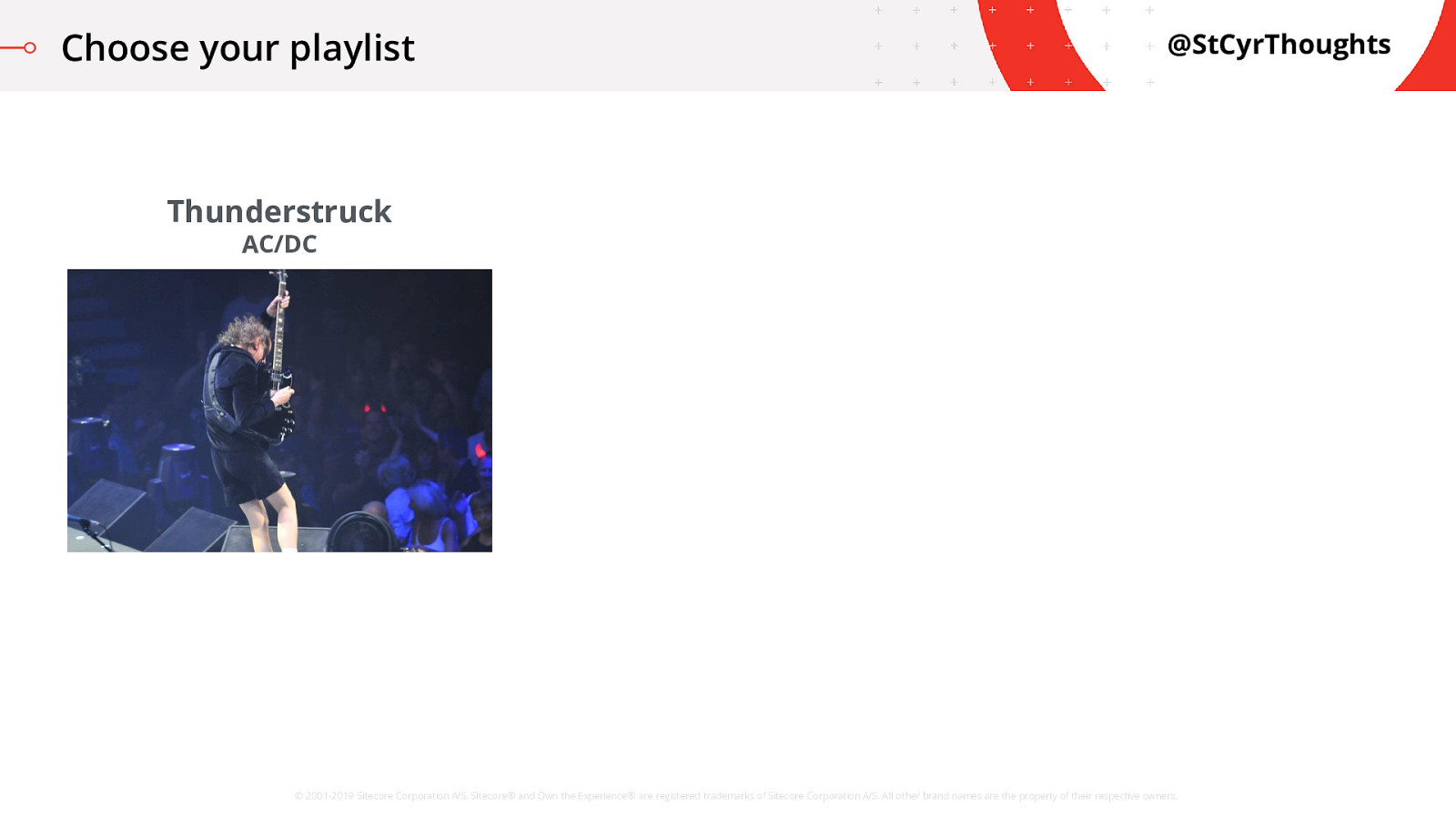
Choose your playlist
First up, is Thunderstruck by AC/DC
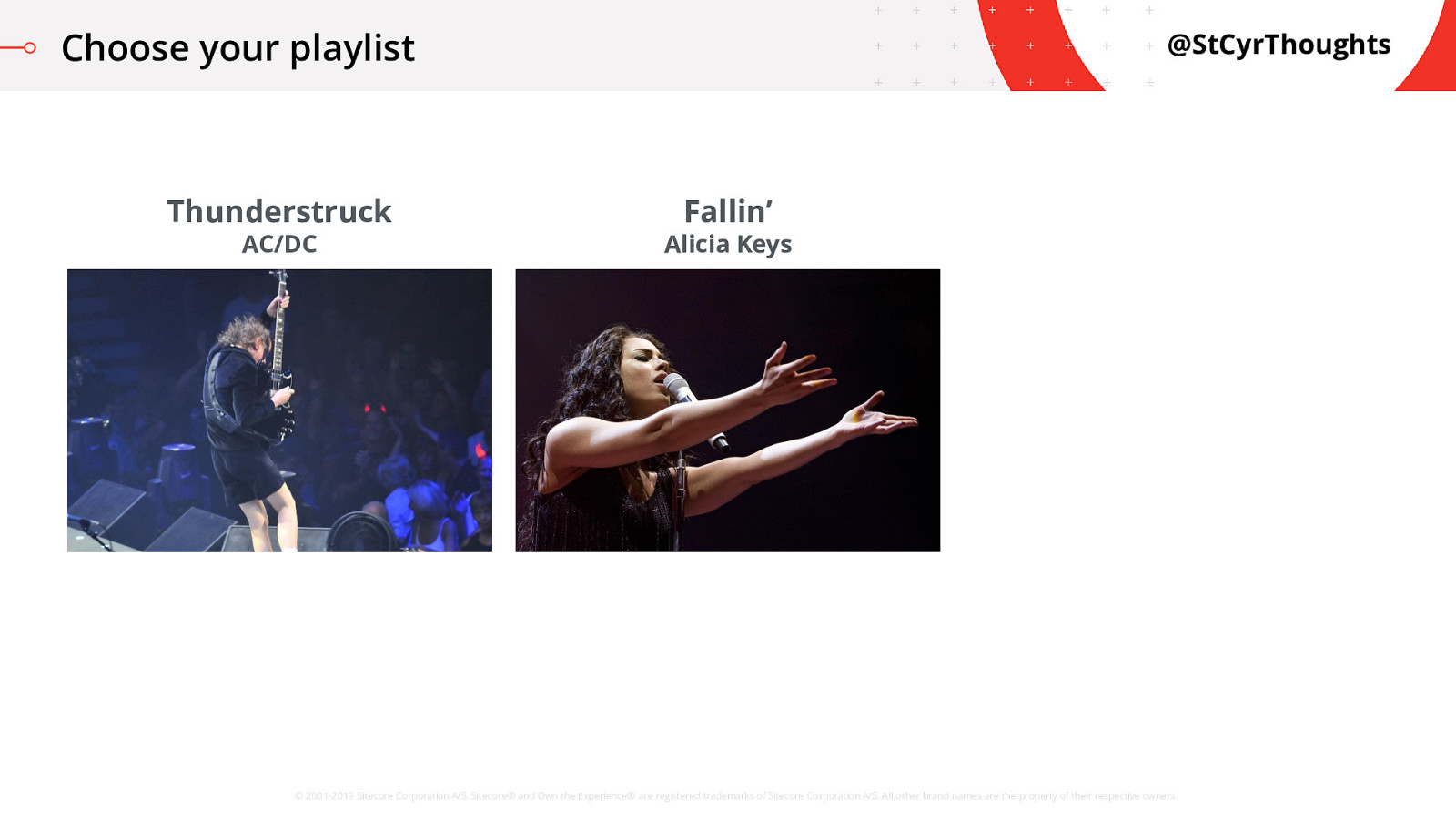
Choose your playlist
We also have Fallin’, from Alicia Keys
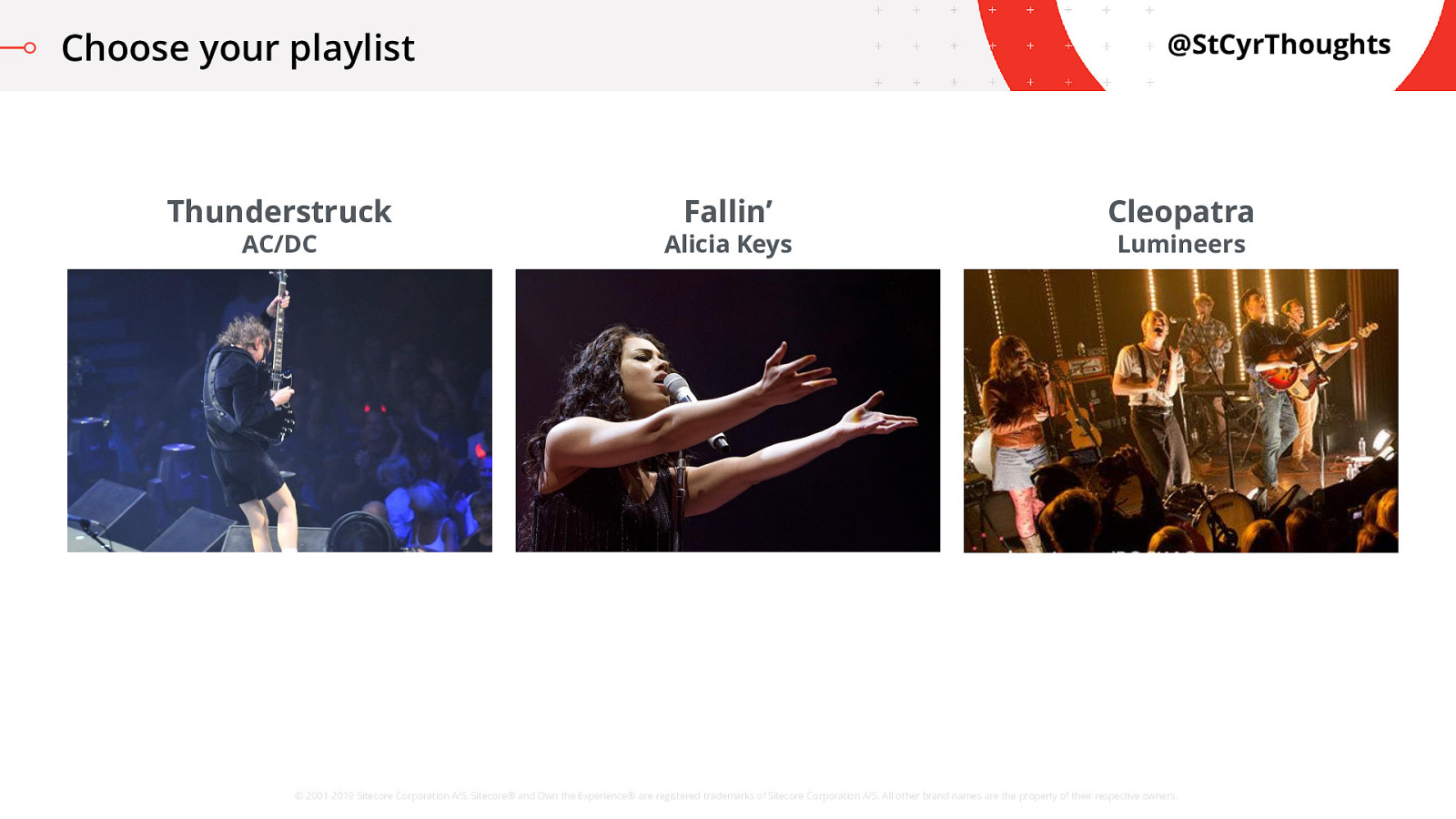
Choose your playlist
And finally Cleopatra, from the Lumineers I want you to think about which one you would pick. If you could only listen to one, right now, which of these songs would you add to your playlist?
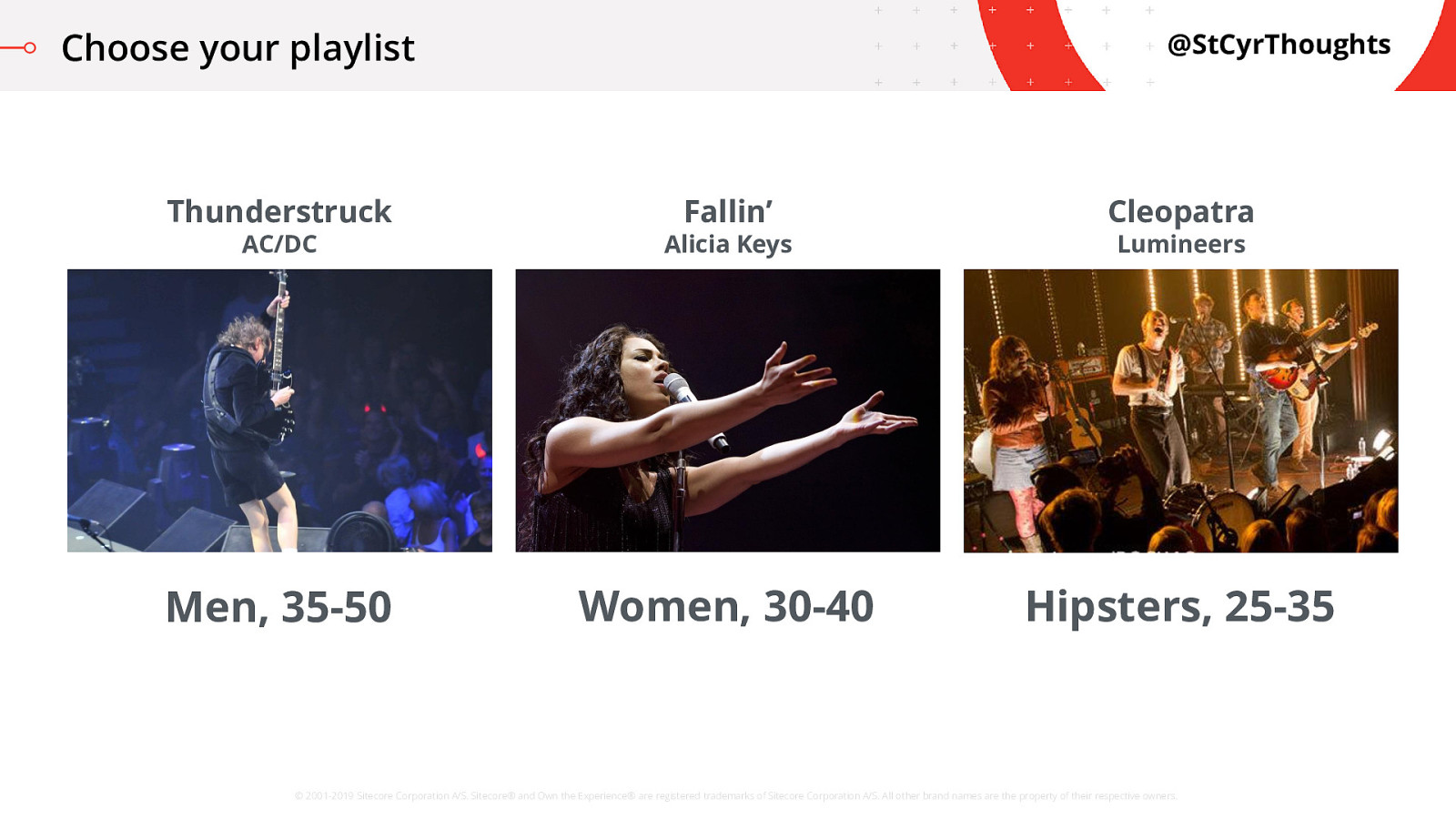
Choose your playlist
Don’t see yourself in that?
Me neither. I have ALL of these songs.
What I want to listen to depends more on what I’m doing.
If it’s a hot summer day and I’m out for a drive to the local Timmy’s, I’m probably more likely to roll down the windows and blast some AC/DC while drumming on the steering wheel.
However, if I’m at home just relaxing, I might want to put on some Alicia Keys, dance like nobody’s watching, and sing at full volume.
Now, if I need to get some work done on some blogs or presentations, though, throwing on some Lumineers let’s me get creative and calm. Context trumps whatever demographics we’re looking at. Was your choice influenced by this room, this presentation, last night’s party? This morning’s early rise?

Diversity - Data and Team Diversity
Which is probably a good place to switch over to talking about data diversity… and team diversity.
Nothing helps you be a more ethical organization than by having a collection of ideas from different view points. The analogy of “two heads are better than one” hints at this… we all bring our own unconscious biases to the table. Even if we are trying our best to think of others and how they should be treated, nothing replaces the collective voices of different experiences.
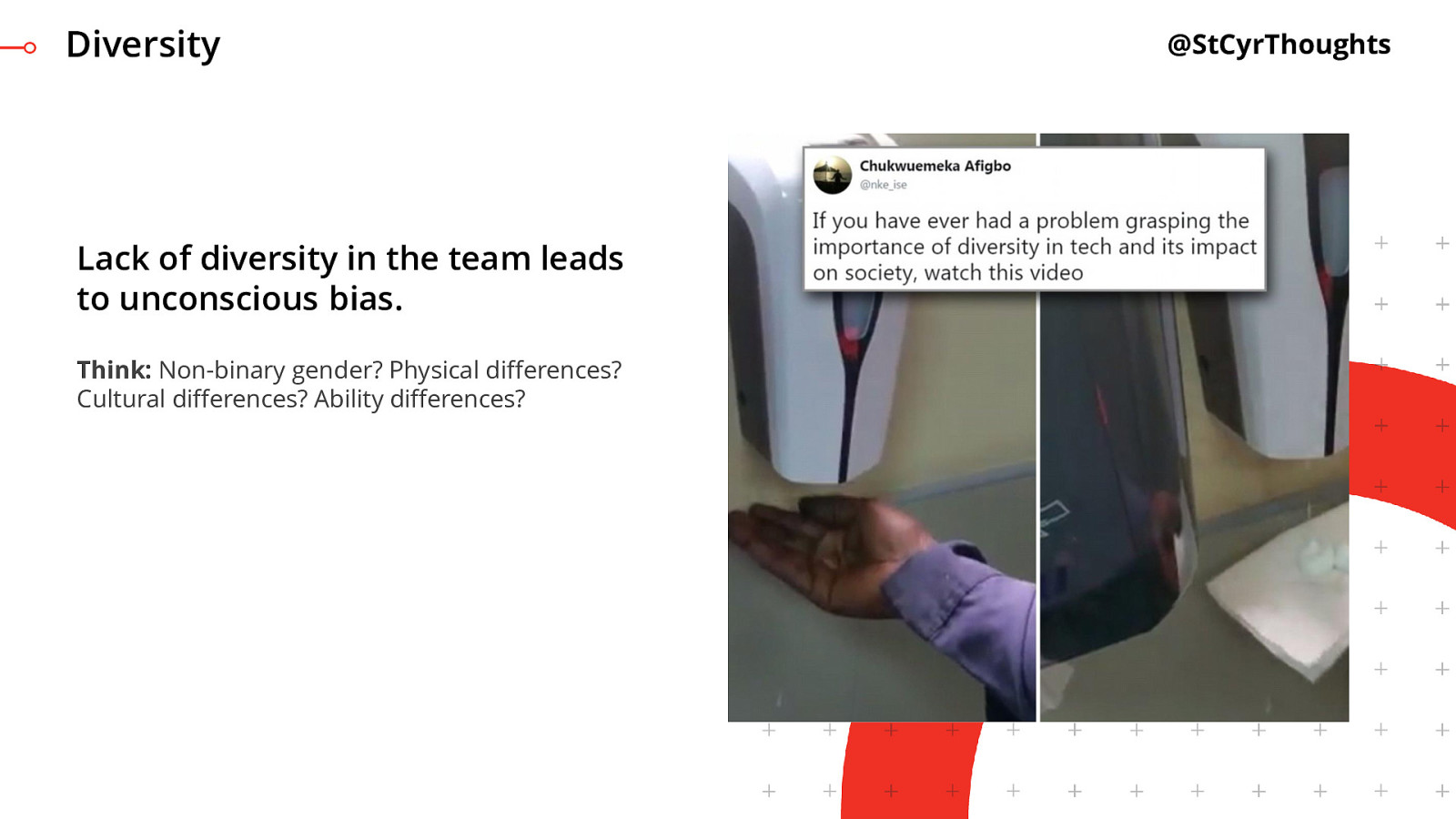
Lack of diversity in the team leads to unconscious bias
One example, though not particularly a machine learning one, is about a racist soap dispenser at a Facebook office in Africa. If you’ve seen the video, essentially what happens is that the sensors cannot detect dark skin. Employees needed to hold a piece of white tissue paper under the dispenser to get any soap to wash their hands. If you had even a SINGLE person with darker skin on your test or development team, this issue doesn’t happen.
And it’s not like the team building this was hatching together a plan in their office to take down Facebook from the inside by making their employees unable to wash their hands. I mean, I’m pretty sure.
These are folks like you and me, just trying to hit a deadline, doing what they can. This is why it’s an unconscious bias.
Another example, in many circles gender is seen as Male, or Female. Many machine learning models and algorithms get built entirely around this concept and try to predict behavior on whether you are a man or a woman. What happens when a non-binary individual gets scored by that algorithm? Nobody was trying to be mean when they put that model together, it simply does not even occur to them to include that as an option. A non-binary individual on the team would immediately point it out and identify the issue, leading to better data and a better model.

Diverse teams can more easily break into other markets and deliver better experiences
And this diversity also allows you to have a better story for customers in different cultures and regions. Allowing your team to have a diversity of ideas, but also cultures, family histories, geographic locations, all of this allows you to get a better solution that can work for every individual.
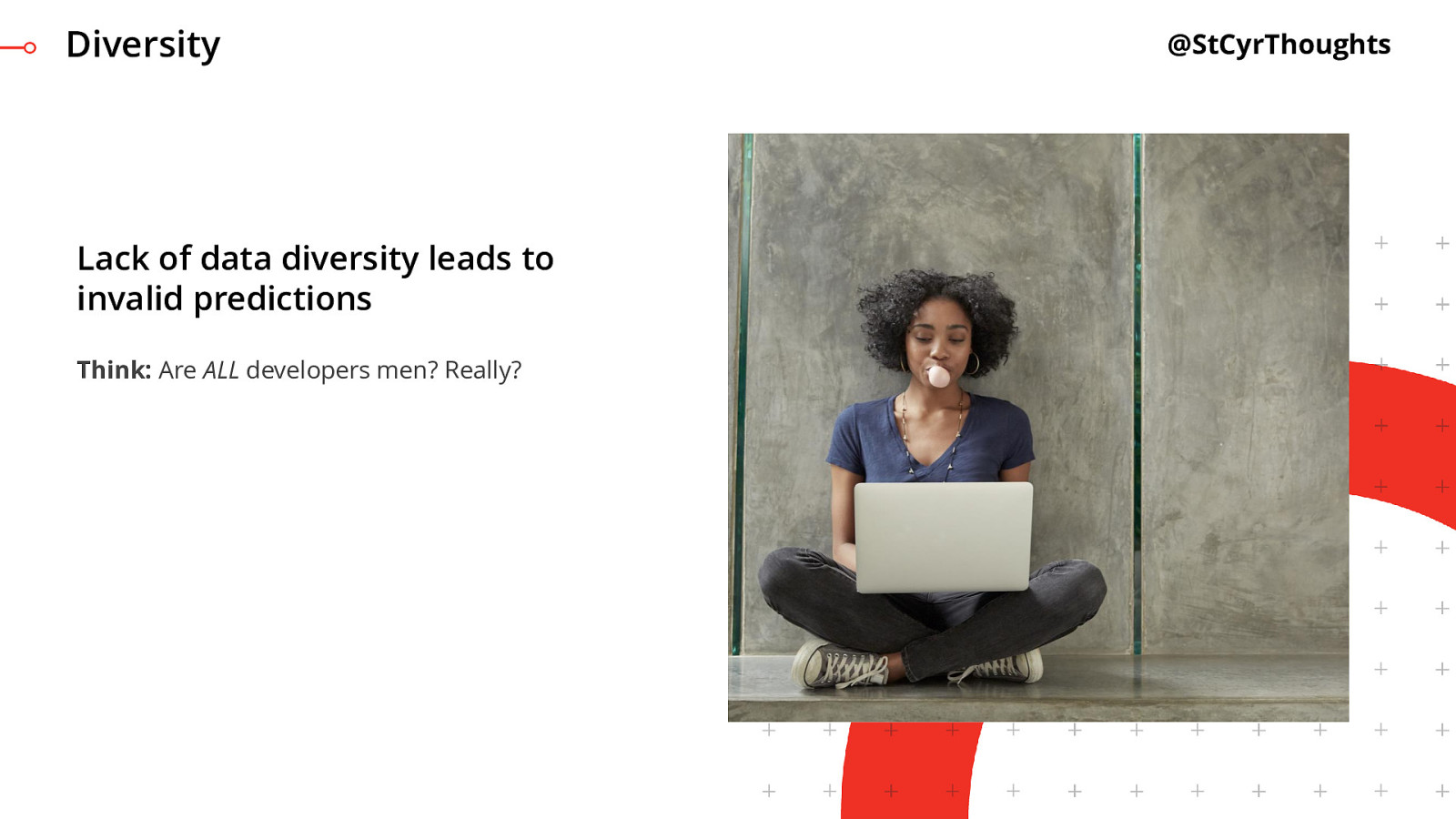
Lack of data diversity leads to invalid predictions
We need to ensure diversity on our teams to help find issues in our process, but we also need diversity in our data. I was told a story by somebody who attended an event of how they used some application at a kiosk for recommending tracks and it refused to acknowledge that she was a developer and classified her instead as a marketer. The model simply did not have the data diversity to recognize a woman as a developer.

Diverse data allows your algorithm to cover the entirety of your audience and increase accuracy of results
You might say “well, we’re going to get it right most of the time” but nobody hears the stories about the times you got it right. You will hear the stories about when you get it wrong. So we need to make sure that the predictions are covering our whole audience and improving all of their experiences, not just some.

Data Diversity and Image Recognition
Now, because data diversity is so key, I wanted to take a look at an example of a lack of diversity and the problems it can cause with image recognition.
A quick shout out to Angie Jones at AppliTools who did a great video on explaining machine learning for newbies, which inspired this example.

Comparing Apples and Oranges
We’ve told the machine the image on the left is an Orange,

Comparing Apples and Oranges
and the image in the middle is an Apple.

Comparing Apples and Oranges
Then we ask the machine to tell us what this new picture is. Well, it likely thinks this is an orange. Why?
Because it doesn’t have diverse enough data. It also has no idea that the stem or skin texture are the important parts of the image.
If you look at them, the new image has a round shape in the middle is roughly the same as the shape in the orange picture, and the backgrounds are identical. To the machine, the Orange image looks way more similar then the image we’ve told it is an Apple.
In fact, the machine learning may have only learned that ‘Orange’ means light background with a round thing and ‘Apple’ means dark background with a round thing. We need to have more available comparison points for the model to work.

Can you test for this?
Now this is sort of a bonus thing I wanted to bring up. If you’re into cool math algorithms you can probably dig into this stuff a whole lot deeper than I can, but there is great work being done to define ways of testing machine learning models and algorithms to find unfair bias. It should be noted, algorithms NEED bias to work. It’s kind of hard to make a prediction if every single outcome is equally likely regardless of the variable. However, when testing we are looking for unwanted discriminatory bias in the system.

Fairness Testing - Association Tests
Several researches have been investigating different ways to run ‘association tests’. This allows you to measure the correlation between different data points in an attempt to look for possible bias. Specifically, trying out sensitive user attributes (such as race or gender) and then analyze outcomes to see if the outcomes change unfairly based on that property.
There is a tool you can look into from Cornell University called ‘FairTest’ which uses an “unwarranted associations” framework. This checks data-driven applications for unfair use treatment.
REFERENCES: https://abhishek-tiwari.com/bias-and-fairness-in-machine-learning/ UA and FairTest: https://arxiv.org/abs/1510.02377 FairML: https://blog.fastforwardlabs.com/2017/03/09/fairml-auditing-black-boxpredictive-models.html
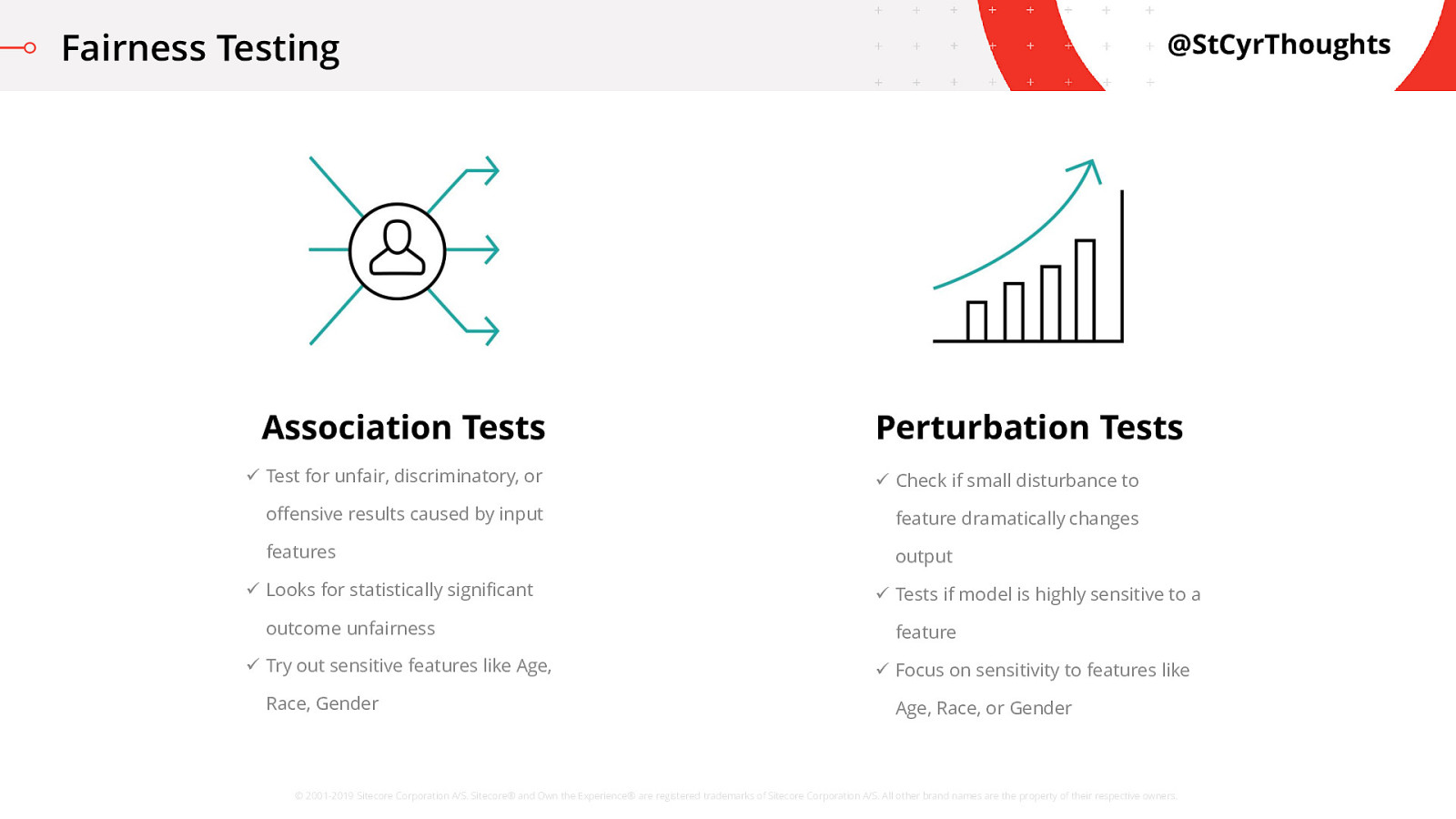
Fairness Testing - Perturbation Tests
The goal here is to cause a deliberate disturbance in the input data on a selected feature and check for a dramatic change in the output. This is to test if the model is sensitive to that specific feature. For example, you might slightly adjust the age of an individual and measure how much of a change in the outcome occurs. If there is a big change in the prediction, then the model was very sensitive to age.
Something you can check out is FairML which is a Python library available on GitHub which uses orthogonal projection to measure the dependence of the model on each feature.
If testing or neat math applications are your thing, I’d encourage you to take a look online and read up on some of this!
REFERENCES: https://abhishek-tiwari.com/bias-and-fairness-in-machine-learning/ UA and FairTest: https://arxiv.org/abs/1510.02377 FairML: https://blog.fastforwardlabs.com/2017/03/09/fairml-auditing-black-box-predictive-models.html

Ethics all the things!
With that, however, our time has come to a close. I hope that you have a renewed appreciation for how we all have an impact on the ethical applications of software solutions, including machine learning.
Remember to try to think about these three things:

Integrity, Individualize, Diversity
How can YOU reinforce the integrity within your organization? How can YOU deliver solutions that work for individuals, regardless of their demographics? How you YOU help your team to be more diverse and ensure better data diversity to reduce unconscious bias?
We’re all in this together. Hopefully the next time you’re working on something you take the time to stop and think… SHOULD we be doing this?

Thank you.
Thank you very much for listening.
Photo by Charles Strebor (https://www.flickr.com/photos/rantz/)

We are all guardians of the digital spaces our audiences live in. We control what data is collected, how it is used, how it is stored, and potentially how it can be abused. With advancements in Machine Learning, personalization, and individualization, we are looking at a new world of improved customer experiences. How do we make sure this is done in an ethical way? How do we protect individual privacy? How do we avoid bias in our algorithms? This session will explore these questions and others and empower the audience to take ownership of these issues.
 for free. You
can too.
for free. You
can too.
Resources
The following resources were mentioned during the presentation or are useful additional information.
-
Soul in the Machine
This blog series, related to the Who Watches the Watchers presentation, goes into some depths of elements touched on in the presentation